Traitement des données de ventes de jeux vidéo
Projet de traitement et d'analyse de données ouvertes sur les ventes mondiales de jeux vidéo.
Dans le cadre de cette SAÉ, j'ai utilisé un ensemble de données ouvertes de Kaggle concernant les ventes de jeux vidéo physiques à travers le monde. L'objectif était de traiter ces données à l'aide de Python et de créer une interface utilisateur avec Tkinter pour visualiser les résultats.
Importation et nettoyage des données
Objectif : Importer et nettoyer les données pour l'analyse
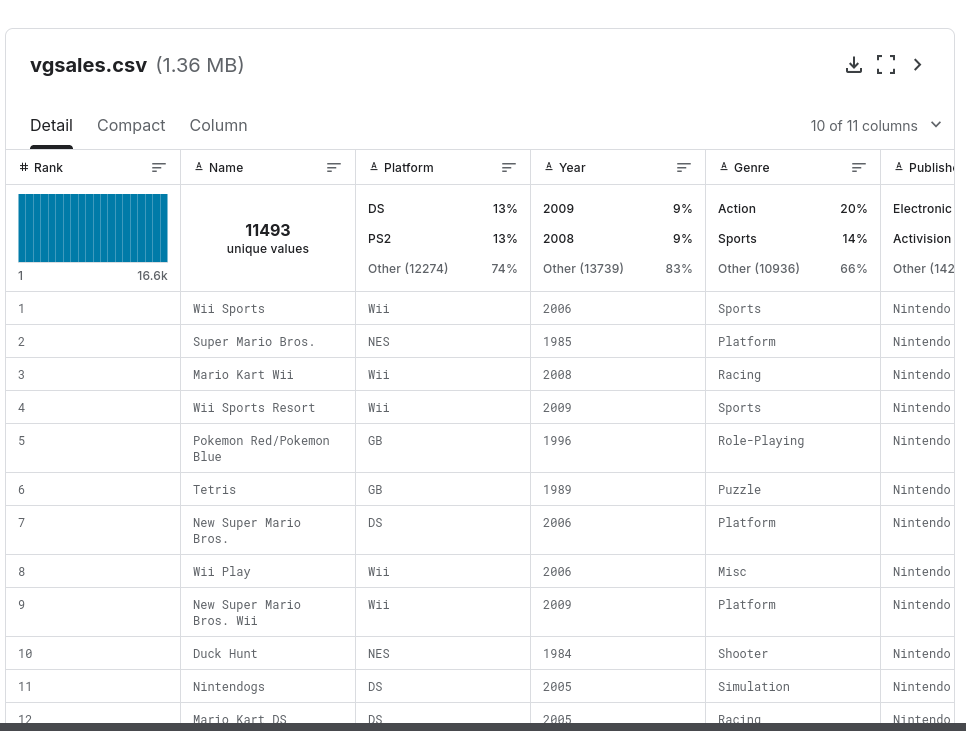
J'ai commencé par importer les données depuis un fichier CSV et j'ai effectué un nettoyage des données pour m'assurer de leur qualité. Cela incluait la gestion des valeurs manquantes et la correction des formats de données comme la suppression des NAN, incompatible avec le format Integer.
Trace
Autoévaluation
Le nettoyage des données a été effectué comme prévu.
Analyse des données
Objectif : Créer des traitements en Python
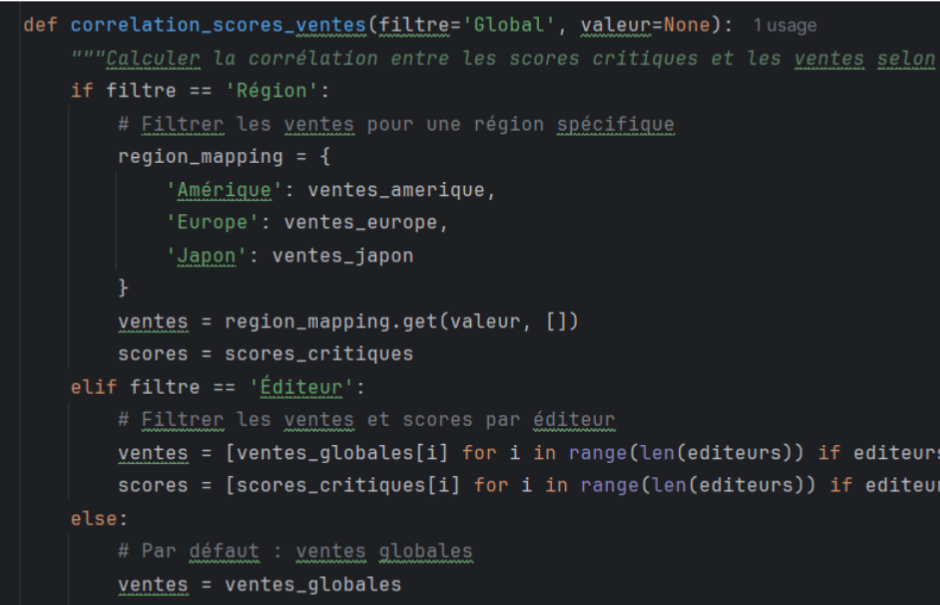
J'ai effectué diverses analyses sur les données, notamment des statistiques descriptives, des visualisations de données, et des analyses de tendances pour comprendre les ventes de jeux vidéo à travers le monde.
Trace
Autoévaluation
L'analyse des données a été bien menée, mais certaines visualisations pourraient être améliorées.
Création de l'interface utilisateur avec Tkinter
Objectif : Créer une interface utilisateur pour visualiser les résultats de l'analyse
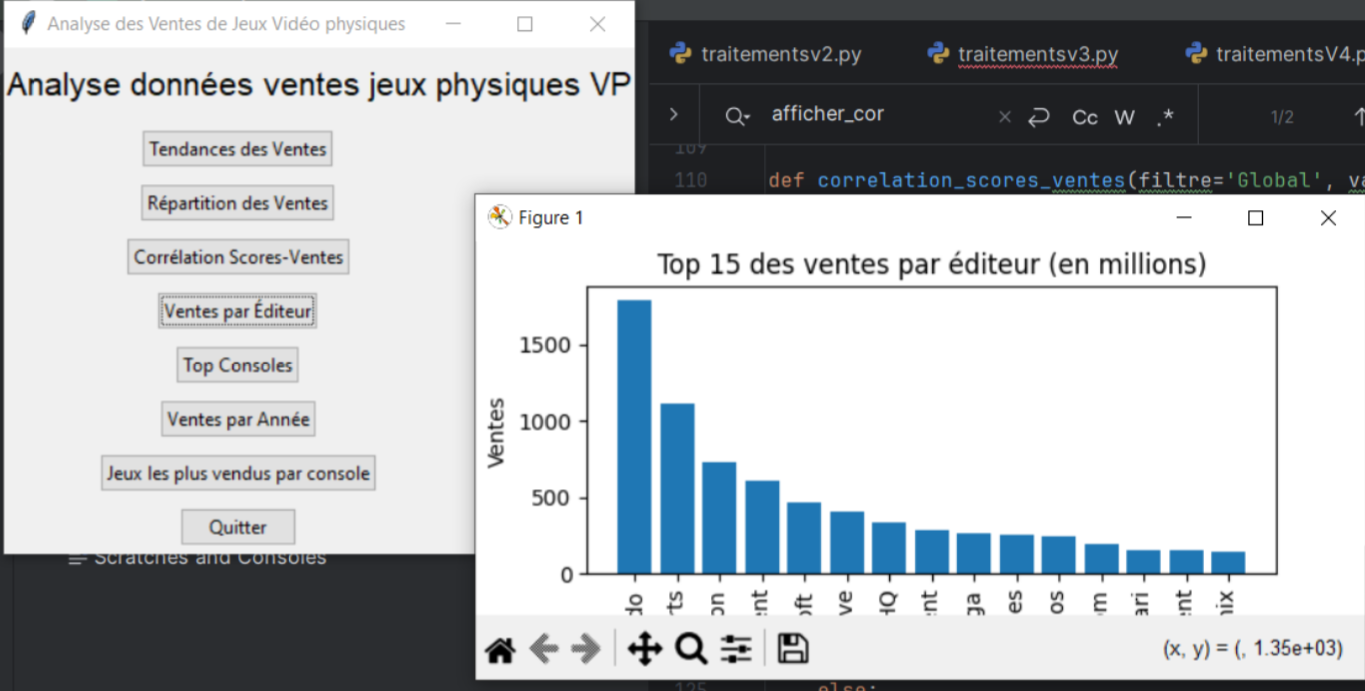
J'ai développé une interface utilisateur avec Tkinter pour permettre aux utilisateurs de visualiser les résultats de l'analyse des données de manière interactive. Cela incluait des graphiques et des tableaux pour présenter les données.
Trace
Autoévaluation
L'interface utilisateur est fonctionnelle et intuitive, mais quelques améliorations pourraient être apportées pour une meilleure expérience utilisateur.
Conclusion : Ce projet était intéressant, car il permettait de mettre en lien données réelles via opendata, et visualisations par code.
La prochaine étape serait d'utiliser une base de données SQL (SGBD) afin de stocker ces informations de manière organisée.


